
Cload Computing

klikdata.co.id
Definisi Cloud Computing
Apa itu Cloud Computing? Cloud Computing (dalam bahasa
Indonesia disebut komputasi awan) adalah proses pengolahan daya komputasi (baik
CPU, RAM, Network Speeds, Software, OS maupun Storage) melalui jaringan
(biasanya lewat internet). Jadi transfer data yang terjadi bukan secara fisik
dan sumber daya komputasi yang dimiliki berada di lokasi pengguna yang memakai
layanannya.
Manfaat Cloud Computing
Komputasi awan sebenarnya jadi menurunkan permintaan
hardware dan software dari sisi si pengguna. Satu-satunya hal yang harus bisa
dijalankan/dilakukan oleh si pengguna adalah software interface dari sistem
komputasi awan, yang bisa jadi sesederhana saja semacam browser web. Ini
pastinya bisa membantu mengurangi pekerjaan pengguna dengan adanya teknonologi
jaringan Cloud yang tanggap dan otomatis menyelesaikan masalah-masalah IT
lainnya.
Bila Anda bukan
dari pihak korporat/pebisnis, Anda juga sebenarnya sudah menggunakan teknologi
komputasi awan. Anda mungkin tidak sadar, beberapa layanan cloud populer yang
telah banyak digunakan semacam email tools GMail, Hotmail atau Yahoo bahkan
sudah didukung teknologi ini.
Saat
mengakses/memakai layanan email, data Anda akan disimpan di server cloud, bukan
di komputer Anda. Teknologi dan infrastruktur di belakang cloud memang tidak
tampak. Jadi, tidak penting lagi apakah layanan cloud didasarkan pada HTTP,
XML, Ruby, PHP atau teknologi spesifik lainnya sejauh itu masih user-friendly
dan juga fungsional tentunya. Anda sebagai pengguna bisa terhubung ke sistem
cloud dari perangkat pribadi Anda sendiri semacam laptop, atau ponsel.
Komputasi awan
juga memang memanfaatkan bisnis kecil secara efektif dengan sumber daya yang
terbatas. Teknologi atau layanan ini bisa kasih akses ke usaha kecil menengah
untuk teknologi yang sebelumnya berada di luar jangkauan mereka. Cloud
computing kini banyak sekali membantu usaha kecil untuk mengubah biaya
pengeluaran mereka malah menjadi untung.
Tipe-tipe Cloud
Ada empat macam/tipe cloud yang berbeda yang dapat dipakai,
sesuai dengan kebutuhan bisnis. Berikut adalah keempatnya.
Private Cloud
Private cloud ini berarti sumber daya cloudnya digunakan
untuk satu organisasi tertentu saja (secara privat, tidak dibagi ke
pengguna/organisasi lain). Metode ini lebih banyak digunakan untuk interaksi
semacam intra-bisnis, dimana sumber daya cloudnya dapat diatur, dimiliki, dan
dioperasikan oleh organisasi yang sama.
Community Cloud
Community cloud mengacu pada penggunaan source bagi
komunitas dan organisasi.
Public Cloud
Jenis cloud ini biasanya dipakai untuk interaksi B2C
(Business to Consumer). Public cloud menggunakan sumber daya komputasi yang
dimiliki, diatur dan dioperasikan oleh pemerintah.
Hybrid Cloud
Jenis cloud yang satu ini dapat digunakan untuk kedua jenis
interaksi B2B (Business to Business) atau B2C (Business to Consumer). Jadi,
sumber daya komputasi terikat bersama tapi dengan cloud yang berbeda.
Grid Computing

nesabamedia.com
Grid Computing merupakan sebuah sistem sumber komputer yang
sudah terdistribusi. Sistem yang ada di dalam jaringan tersebut bisa
mengerjakan berbagai permasalahan besar yang rumit. Setiap komputer akan
bekerja di bawah protokol yang sama sehingga bisa berfungsi sebagai super
komputer virtual sehingga bisa berbagi sumber daya.
Komputer tersebut harus terkoneksi dengan perangkat fisik
melalui internet atau jaringan lokal. Bisa juga komputer-komputer tersebut bisa
saling berkomunikasi melalui aplikasi yang memang mendukung untuk mennjalankan
tugas tersebut. Nanti administrator berperan mengakses serta mengendalikan
sumber daya pada tiga tempat yang berbeda.
Cara Kerja Grid Computing
Lalu bagaimana dengan cara kerja Grid Computing? Setiap
komputer yang ada di dalam jaringan akan berperan sebagai superkomputer.
Superkomputer tersebut kemudian harus mengakses data pemrosesan yang memilikin
kapasitas sangat besar. Grid Computing juga akan merencanakan sebuah
permasalahan seperti pemodelan cuacara dan simulasi gempa.
Selain itu, arsitektur jaringan juga bisa digunakan untuk
menstabilkan beban serta koneksi jaringan yang sudah berlebih. Model ini
memanfaatkan software pemrosesan yang sifatnya paralel yang nantinya akan
membagi komputer di antara ribuan komputer.
Kemudian prosesnya berlanjut dengan mengumpulkan lalu
menggabungkan hasilnya sehingga menjadi satu solusi. Berkaitan dengan keamanan,
Grid Computing dibatasi di dalam organisasi yang sama.
Bagian-bagian Grid Computing
Data Grid: seperangkat data yang sudah diatur untuk
didistribusikan sehingga menjadi sebuah media lingkungan virtual. Data tersebut
akan mendukung manajemen data serta berbagai penggunaan yang terkontrol
CPU Scaveging Grids: sebuah sistem yang merupakan proyek di
dalam salah satu komputer dapat berpindah ke komputer yang lainnya sesuai
dengan kebutuhannya. Selian itu, bagian ini juga mampu melakukan perpindahan
dan penggunaan lebih mudah sehingga bisa mencapai tujuan yang diinginkan
Virtualisasi

liesfors.wordpress.com
Apa itu virtualisasi?
Virtualisasi adalah sebuah proses
berbasis software atau virtual, representasi dari sesuatu, baik itu aplikasi
virtual, server, ruang penyimpanan, dan koneksi. Virtualisasi merupakan salah
satu cara yang paling efektif untuk mengurangi ongkos IT sekaligus meningkatkan
efisiensi untuk segala macam bisnis.
Sebagai contoh, bayangkan Anda memiliki tiga server fisik
dengan kegunaannya masing-masing. Server pertama merupakan mail server, kedua
adalah web server, dan yang terakhir adalah aplikasi internal. Setiap server
sudah memiliki kapasitas 30%. Akan tetapi, karena server aplikasi adalah yang
penting untuk operasional, Anda harus menjaga performanya dan server ketiga
yang menghostingnya.
Adalah hal mudah dengan menjalankan tugas berbasis individu
pada server individual pula, seperti satu server, satu sistem operasi, satu
tugas, bukan satu server yang menjalankan tugas ganda. Dengan virtualisasi,
Anda bisa membagi mail server menjadi satu yang unik sehingga bisa memegang
tugas mandiri sehingga server aplikasi internal bisa dimigrasikan.
Tipe-tipe Virtualisasi
Pada saat ini, mayoritas virtualisasi di dunia ada pada
virtualisasi server. Tiga tipe utama dari virtualisasi server adalah sebagai
berikut:
Virtualisasi sistem operasi (Container)
Artinya membuat representasi mandiri dari sistem operasi
yang sudah ada agar bisa membuat aplikasi di lingkungan tertentu. Setiap
container akan mencerminkan versi dari sistem operasi yang sudah ada dan juga
patch level.
Emulasi hardware
Ini merepresentasikan lingkungan hardware komputer di
software, sehingga satu komputer bisa diinstal beberapa sistem operasi.
Paravirtualisasi
Sebuah layer tipis software yang mengkoordinasikan akses
dari beberapa sistem operasi yang ada di hardware.
Cara Kerja Virtualisasi
Sebuat software yang disebut hypervisor memisahkan sumber
daya fisik dari lingkungan virtual. Hypervisor bisa berdiri di atas sebuah
sistem operasi atau bisa diinstal langsung ke hardware, dan kebanyakan perusahaan
melakukan hal itu. Hypervisor mengambil sumber daya fisik dan membaginya
sehingga lingkungan virtual bisa menggunakannya.

indonesiancloud.com
Sumber daya dipartisi sesuai kebutuhan dari sumber daya
fisik ke banyak lingkungan virtual. Pengguna berinteraksi dan menjalankan
komputasi di dalam lingkungan virtual. Mesin virtual ini berfungsi sebagai file
single data. Seperti kebanyakan file digital, ini bisa dihapus dari satu
komputer ke komputer lainnya, dibuka, dan dikerjakan secara bersama-sama.
Distributed Computing

Tujuan utama dari sistem komputasi terdistribusi adalah
untuk menghubungkan setiap pengguna dengan sumber daya yang terpisah secara
fisik ke dalam suatu sistem dengan menggunakan cara yang terkoordinasi. Dan
dengan memerlukan kapasitas yang lebih besar dari kapasitas individual
komponennya.
Openness
merupakan properti dari sistem terdistribusi dimana setiap sub-sistem secara
terus-menerus terbuka untuk berinteraksi dengan sistem yang lain. Salah satu
masalah yang dihadapi dalam usaha menyatukan sumber daya yang terpisah ini
antara lain adalah skalabilitas, dapat atau tidaknya sistem tersebut
dikembangkan lebih jauh untuk mencakup sumber daya komputasi yang lebih banyak.
Konsekuensinya, sistem terdistribusi terbuka memberikan
beberapa tantangan berikut.
Monotonicity
Sesuatu yang telah dipublikasikan dalam sistem terbuka (open
system) maka tidak dapat diambil kembali.
Pluralism
Subsitem-subsistem berbeda dalam sistem open distributed
dapat mempunyai informasi yang berbeda dan mungkin menyebabkan konflik. Tidak
ada pengatur kebenaran sentral dalam sistem open distributed.
Unbounded Nondeterminism
Subsistem-subsistem dapat naik dan turun, dan link
komunikasi dapat masuk dan keluar antar subsistem dalam sistem open
distributed. Karena itu, waktu yang diperlukan untuk menyelesaikan suatu
operasi tidak dapat dibatasi dan dipastikan.
Kelemahan dan Kerugian
Jika tidak
direncanakan dengan tepat, suatu distributed system dapat menurunkan
reliabilitas total dari komputasi jika ketidak-tersediaan dari suatu node dapat
menyebabkan gangguan bagi node-node lain. Troubleshooting dan diagnosing
terhadap masalah dalam distributed system dapat menjadi lebih sulit, karena
perlu analisis yang berkaitan dengan node jauh atau menginspeksi komunikasi
antar node di dalam sistem.
Banyak tipe
komputasi tidak cocok bagi lingkungan terdistribusi, biasanya yang berhubungan
dengan jumlah komunikasi jaringan atau sinkronisasi yang dibutuhkan antar node.
Jika bandwidth, latency, atau persyaratan komunikasi begitu signifikan, maka
tidak ada keuntungan dari distributed computing dan kinerja dapat lebih burukk
daripada lingkungan non-distributed.
Arsitektur
Terdapat
banyak arsitektur dari perangkat keras dan perangkat lunak yang sangat
bervariasi dan digunakan untuk distributed computing atau komputasi
terdistribusi. Pada tingkat yang rendah, perlu adanya penghubung antara CPU
dengan CPU lainnya yang berjumlah banyak. Pada tingkat yang lebih tinggi perlu
dibutuhkannya interkoneksi untuk menghubungkan CPU yang ada dengan sistem
komunikasi.
Arsitektur
umum yang digunakan oleh Distributed Computing atau Komputasi Terdistribusi
yaitu sebagai berikut.
1. Client-server: klien menghubungi server untuk pengambilan
data, kemudian server memformatnya dan menampilkannya ke pengguna.
2. 3-tier architecture: kebanyakan aplikasi web adalah
3-Tier.
3. N-Tier architecture: N-Tier biasanya menunjuk ke aplikasi
web yang menyalurkan lagi permintaan kepada pelayanan enterprise. Aplikasi
jenis ini paling berjasa bagi kesuksesan server aplikasi.
4. Tightly coupled (clustered): biasanya menunjuk kepada
satu set mesin yang sangat bersatu yang menjalankan proses yang sama secara
paralel, membagi tugas dalam bagian-bagian dan kemudian mengumpulkan kembali
dan sebagai hasil akhir.
5. Peer-to-peer: sebuah arsitektur dimana tidak terdapat
mesin khusus yang melayani suatu pelayanan tertentu atau mengatur sumber daya
dalam jaringan. Dan semua kewajiban dibagi rata ke seluruh mesin, yang dikenal
sebagai peer.
6. Space based: mengacu ke suatu infrastruktur yang membuat
ilusi atau virtualisasidari satu ruang-alamat (address-space) tunggal. Data
secara transparan direplikasi sesuai dengan kebutuhan aplikasi.
7. Mobile code: berdasarkan prinsip arsitektur mendekatkan
pemrosesan ke sumber data.
8. Replicated repository: dimana repository dibuat
replikanya dan disebarkan ke dalam sistem untuk membantu pemrosesan online/offline
dengan syarat keterlambatan pemaharuan data dapat diterima.
Map Reduce

community-java.com
Apa itu MapReduce?
MapReduce adalah paradigma pemrograman yang memungkinkan
skalabilitas besar-besaran di ratusan atau ribuan server dalam cluster Hadoop.
Sebagai komponen pemrosesan, MapReduce adalah jantung dari Apache Hadoop.
Istilah "MapReduce" mengacu pada dua tugas terpisah dan berbeda yang
dilakukan oleh program Hadoop. Pertama adalah map job, yang mengambil satu set
data dan mengubahnya menjadi set data lain, di mana elemen individual dipecah
menjadi tupel (sepasang key value).
Setelah itu, reduce job akan mengambil output dari peta
sebagai input, kemudian menggabungkan tupel data tersebut ke dalam kumpulan
tupel yang lebih kecil. Seperti yang disiratkan oleh urutan nama MapReduce,
reduce job selalu dilakukan setelah map job.
Pemrograman MapReduce menawarkan beberapa manfaat untuk
membantu Anda mendapatkan wawasan berharga dari big data Anda:
1. Skalabilitas. Bisnis dapat memproses petabyte data yang
disimpan di Hadoop Distributed File System (HDFS).
2. Fleksibilitas. Hadoop memungkinkan akses yang lebih mudah
ke berbagai sumber data dan berbagai jenis data.
3. Kecepatan. Dengan pemrosesan paralel dan pergerakan data
minimal, Hadoop menawarkan pemrosesan data dalam jumlah besar dengan cepat.
4. Sederhana. Developer dapat menulis kode dalam pilihan
bahasa, termasuk Java, C++ dan Python.
Cara Kerja MapReduce
Setelah mengetahui apa itu MapReduce, selanjutnya kita akan
mempelajari bagaimanacara kerja alat ini. Hadoop membagi pekerjaan MapReduce
menjadi beberapa tugas. Seperti yang sudah disebutkan sebelumnya, ada dua jenis
tugas, yaitu:
1. Map job (pemisahan & pemetaan).
2. Reduce job (shuffling & mengurangi).
Proses eksekusi keduanya dikendalikan oleh dua jenis entitas
yang disebut sebagai:
1. Job Tracker: Bertindak seperti master (bertanggung jawab
untuk menyelesaikan pekerjaan yang dikirimkan).
2. Multiple Task Trackers: Bertindak seperti slave,
masing-masing melakukan pekerjaan tersebut.
Untuk setiap pekerjaan yang dikirimkan untuk dieksekusi
dalam sistem, ada satu job tracker yang berada di Namenode dan ada beberapa
task tracker yang berada di Datanode.
Pekerjaan ini dibagi menjadi beberapa tugas yang kemudian
dijalankan ke beberapa datanode dalam
sebuah cluster. Ini adalah tanggung jawab job tracker untuk mengoordinasikan
aktivitas dengan menjadwalkan tugas untuk dijalankan pada data node yang
berbeda.
Eksekusi tugas individu kemudian dijaga oleh task tracker,
yang berada di setiap data node yang menjalankan bagian dari pekerjaan
tersebut. Tanggung jawab task tracker adalah mengirim laporan kemajuan ke job
tracker.
Selain itu, task tracker secara berkala mengirimkan sinyal
'detak jantung' ke job tracker untuk memberi tahu dia tentang status sistem
saat ini. Jadi, job tracker akan melacak kemajuan keseluruhan setiap pekerjaan.
Jika terjadi kegagalan tugas, job tracker dapat melakukan re-schedule pada
setiap task tracker yang berbeda.
No SQL
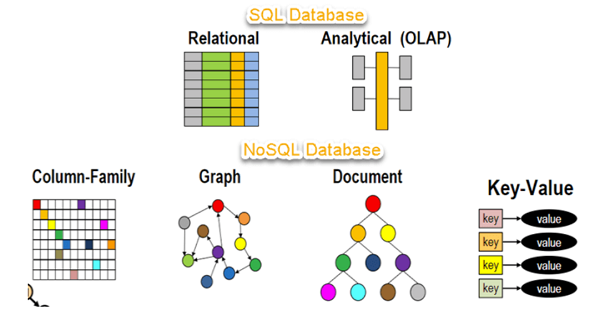
glints.com
Apa Itu noSQL Databases?
Database noSQL adalah Database yang tidak memiliki perintah
SQL dan konsep penyimpanannya semistuktural atau tidak struktural dan tidak harus
memiliki relasi seperti layaknya tabel-tabel MySQL.
Tujuan dari penggunaan database noSQL adalah untuk model
data spesifik dan memiliki skema fleksibel dalam membuat aplikasi modern.
Kebanyakan dalam beberapa kasus penggunaan Database noSQl berfungsi dalam
pengembangan real time application.
Cara kerja database noSQL yakni dengan menggunakan berbagai
model database untuk mengelolah dan mengakses data, seperti dokument,
key-value, grapik, in-memory dan search-engine.
Kita akan mengulas beberapa model database noSQL diatas.
Document, mendefenisikan database sebagai dokumen artinya
penyimpanan data dan proses manipulasinya dalam bentuk objek dokument. Contoh
objek dokument yang sering diterapkan dalam pemograman adalah format Json.
Konsep dari Json merupakan konsep data yang efesien dalam pembangunan aplikasi
karena Json memiliki sifat yang fleksible, semi struktur dan hirarki. Sehingga
memungkinkan program akan lebih mudah dikembangkan karena document akan
menyusaikan penyimpanan data berdasarkan kebutuhan dari aplikasi. Berikut ini
adalah contoh document dengan konsep data Json.
Key-value, defenisi database dengan key-value adalah
penyimpanan data dengan dengan metode key-value (nilai kunci) sebagai tempat
akses data-data. Contoh database yang manganut konsep key-value adalah
dyamondDB.
Grapik, database jenis grafik menggunakan node sebagai
entitas data dan edge sebagai hubungan antar entitas. Setiap edge memiliki node
awalan dan node akhiran. Edge juga menggambarkan hubungan antara oratua-anak,
kepemilikan, tindakan dan lain sebagainya. Tidak ada batasan jumlah suatu node
untuk terhubung dengan node lainnya. Tujuan dari database jenis grapik ini
adalah jejaring media sosial, grafik pengetahuan dan mesin rekomendasi. Untuk
lebih mudah memahi database grafik anda dapat melihat gambar dibawah ini tentang
relasi pertemanan.
In-Memory, Database model ini bekerja dengan menyimpan data
pada memori utama, yang familiar dengan perangkat keras pasti akan tau apa nama
perangakat tersebut? yah… betul nama perangkatnya adalah RAM (Random Access
Memory). Dengan penyimpanan data didalam RAM maka aksesnya akan sangat cepat
sekali. Tidak ada perangkat disk manapun yang mampu menyaingi kecepatan dari
akses langsung ke memori utama (RAM) sekali pun itu SSD (Solid State Disc).
Jika demikian bagaimana jika perangkat (server) mati tentunya seluruh data akan
hilang. Akan tetapi cara kerja database jenis ini tidak seperti itu sepenuhnya,
karna database dala in-memory dapat disimpan dalam sebuah disc penyimpanan
layaknya MySQL dan Postgres. Database in-memory cara kerja penyimpanan datanya
kedalam sebuah disk yaitu dengan cara pengambilan log dan snapshot. Anda dapat
perhatikan gambar dibawah ini untuk menjelaskan cara kerjanya.
Search-Engine, bagi anda yang senang berselancar didunia
maya tentunya pernah memakai google untuk mencari suatu informasi yang berupa
konten data baik itu berupa text, gambar, vidio dan lain-lain. Dalam hal ini
search-engine database digunakan pada saat proses pencarian karena penciptaan
dari konsep database search-engine didedikasikan untuk mesin pencari. Cara
kerja dari search-engine database digunakan untuk mencari data yang sangat
panjang, besar dan tidak terstruktur yakni dengan menggunakan index sebagai
sumber informasi untuk pengoptimalan pencarian.
referensi :
https://www.ensinesia.com/2019/10/pengertian-grid-computing-beserta-cara.html
https://www.nesabamedia.com/
https://indonesiancloud.com/apa-itu-virtualisasi/
http://jaisicamm.blogspot.com/2015/02/distributed-parallel-computing.html
https://wartaekonomi.co.id/read376188/apa-itu-mapreduce
https://muhammadiqbal.art.blog/2019/08/23/apa-itu-database-nosql-dan-jenis-jenis-database-nosql/






No comments:
Post a Comment